Creating a CNN to Classify Dog Breeds using Transfer Learning¶
Here we use transfer learning to create a CNN that can identify dog breed from images. The implemented CNN attains approximately 83% accuracy on the test set.
In Step 4, we used transfer learning to create a CNN using VGG-16 bottleneck features. In this step, we use the bottleneck features from a different pre-trained model.
In addition, we use pre-computed features for all of the networks that are currently available in Keras:
- VGG-19 bottleneck features
- ResNet-50 bottleneck features
- Inception bottleneck features
- Xception bottleneck features
The files are encoded as such:
Dog{network}Data.npz
where {network}, in the above filename, can be one of VGG19, Resnet50, InceptionV3, or Xception. In the following, we pick one of the above architectures, downloading the corresponding bottleneck features, and storing the downloaded file in the bottleneck_features/ folder in the repository.
Obtaining Bottleneck Features¶
In the code block below, we extract the bottleneck features corresponding to the train, test, and validation sets by running the following:
bottleneck_features = np.load('bottleneck_features/Dog{network}Data.npz')
train_{network} = bottleneck_features['train']
valid_{network} = bottleneck_features['valid']
test_{network} = bottleneck_features['test']bottleneck_features = np.load('bottleneck_features/DogResnet50Data.npz')
train_ResNet50 = bottleneck_features['train']
valid_ResNet50 = bottleneck_features['valid']
test_ResNet50 = bottleneck_features['test']
Model Architecture¶
Here we create a CNN to classify dog breed, and summarize the layers of the model by executing the line:
<model's name>.summary()Steps taken to build and implement the CNN architecture:¶
Image dataset augmentation.
As done before, I augmented the input datasets to help improving the algorithm's performance metrics.
Bottleneck features.
Since we are implementing transfer learning from a ResNet50 CNN that was extensively trained for visual recognition in a different dataset, we need to extract only the corresponding bottleneck features from it. This original network can't be used directly to classify dog breeds in our problem as it was not trained using our datasets.
However, we can imagine that the previous ResNet50 CNN is composed of two parts:
- A subnetwork made up of several layers, starting from the input layer up to some intermediate layer $k$. This subnetwork implements a mapping from the input manifold to a lower $n_k$-dimensional vector space. Therefore, due to its reduced dimensionality the $k-th$ layer is a bottleneck layer. Usually, it is expected that the vector of activations nodes in this layer would provide the features (bottleneck features) necessary to represent dog faces in a generic manner in our problem. Finally, we may opt to keep only the bottleneck layer and feed it as input to the model of our choice.
- The second part (or subnetwork) of the previous ResNet50, starting at the $k+1$ layer up to the output layer is discarded and replaced by the layers of our choice tailored specifically to the needs of our problem.
Additional new layers.
As we assume that the bottleneck features were carefully extracted from a related visual recognition problem, we would only add two layer to our new model:
Global average pooling.- It is recommended to reduce each of the feature maps in the bottleneck layer to single values, effectively performing a flattening operation.
Dense linear output layer.- The output of the average pooling is fed into a dense layer whose linear dimension agrees with the number of categories or classes in our problem. We use a typical softmax activation for the nodes in this layer.
Performance expectations.
The transfer learning model should work much better. As shown below it achieves a 83.13% accuracy. This is the probable result of using the knowledge (bottleneck features) gathered by the previous ResNet50 CNN trained extensively in a similar pattern recognition problem.
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.layers import Dropout, Flatten, Dense, Activation
from keras.models import Sequential
ResNet_model = Sequential()
ResNet_model.add(GlobalAveragePooling2D(input_shape=train_ResNet50.shape[1:]))
ResNet_model.add(Dense(133, activation='softmax'))
ResNet_model.summary()
Pre-training analysis:¶
show_image('val_curves/resnet50_val_curves.png')

The figure above shows plots of the ResNet50 pre-trained model accuracy and loss function v.s. number epochs for the training and validation sets respectively. The run was implemented in a separate script using a total of 100 epochs and a batch size of 20 samples. The validation loss decays in-between 1 and 20 epochs with significant gains in accuracy. Beyond this range the model shows signs of overfitting, as the validation reverts to an increasing behavior as we add more epochs. The validation accuracy saturates very quickly around 20 epochs. This suggests that we need about 20 epochs to attain good accuracy and avoid overfitting.
Compile the Model¶
from keras.optimizers import Adamax
ResNet_model.compile(loss='categorical_crossentropy', optimizer=Adamax(lr=0.002), metrics=['accuracy'])
Train the Model¶
Here we train the model in the code cell below. We use model checkpointing to save the model that attains the best validation loss.
We can augment the training data, but this is not a requirement.
#Fit or 'train' model
from keras.callbacks import ModelCheckpoint
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.ResNet50.hdf5',
verbose=1, save_best_only=True)
#Specify number of epochs and batch_size
epochs = 20
batch_size = 20
init_train_time_rsnt50 = time.time()
# Set to True to fit the model to the non-augmented datasets
if False:
h_rsnt50 = ResNet_model.fit(train_ResNet50, train_targets,
validation_data=(valid_ResNet50, valid_targets),
epochs=epochs, batch_size=batch_size, callbacks=[checkpointer], verbose=1)
# Set to True to fit the model to the augmented datasets
if True:
h_rsnt50 = ResNet_model.fit_generator(datagen_train.flow(train_ResNet50, train_targets, batch_size=batch_size),
steps_per_epoch=train_ResNet50.shape[0] // batch_size,
epochs=epochs, verbose=1, callbacks=[checkpointer],
validation_data=datagen_valid.flow(valid_ResNet50, valid_targets, batch_size=batch_size),
validation_steps=valid_ResNet50.shape[0] // batch_size)
end_train_time_rsnt50 = time.time()
tot_train_time_rsnt50 = end_train_time_rsnt50 - init_train_time_rsnt50
print("Training time = {0:.3f} minutes ".format(round(tot_train_time_rsnt50/60.0, 3)))
plotSave_pf_metrics(h_rsnt50, 'rsnt50_cnn_pf_metrics')

Loading the Model with the Best Validation Loss¶
ResNet_model.load_weights('saved_models/weights.best.ResNet50.hdf5')
Testing the Model¶
Hee we evaluate the model on the test dataset of dog images and obtain an accuracy of 83.13%
ResNet50_predictions = [np.argmax(ResNet_model.predict(np.expand_dims(feature, axis=0))) for feature in test_ResNet50]
test_accuracy = 100*np.sum(np.array(ResNet50_predictions)==np.argmax(test_targets, axis=1))/len(ResNet50_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)
Predict Dog Breed with the Model¶
In the following, we write a function that takes an image path as input and returns the dog breed (Affenpinscher, Afghan_hound, etc) that is predicted by the model.
As done in Step 5, the function should involves three steps:
- Extracting the bottleneck features corresponding to the chosen CNN model.
- Supplying the bottleneck features as input to the model to return the predicted vector. Here we note that the argmax of this prediction vector gives the index of the predicted dog breed.
- Using the
dog_namesarray defined in Step 0 of this notebook to return the corresponding breed.
The functions to extract the bottleneck features can be found in extract_bottleneck_features.py, and they have been imported in an earlier code cell. To obtain the bottleneck features corresponding to the chosen CNN architecture, we use the function
extract_{network}
where {network}, in the above filename, should be one of VGG19, Resnet50, InceptionV3, or Xception.
from extract_bottleneck_features import *
def Resnet50_predict_breed(img_path):
# extract bottleneck features
bottleneck_feature = extract_Resnet50(path_to_tensor(img_path))
# obtain predicted vector
predicted_vector = ResNet_model.predict(bottleneck_feature)
# return dog breed that is predicted by the model
return dog_names[np.argmax(predicted_vector)]
Classifier Algorithm¶
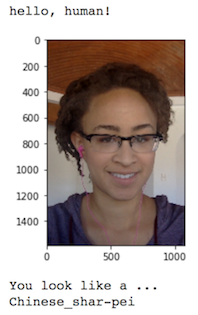
Here we write an algorithm that accepts a file path to an image and first determines whether the image contains a human, dog, or neither. Then,
- if a dog is detected in the image, return the predicted breed.
- if a human is detected in the image, return the resembling dog breed.
- if neither is detected in the image, provide output that indicates an error.
We use face_detector and dog_detector functions developed above. However, we use the CNN from Step 5 to predict dog breed.
Some sample output for the algorithm is provided below.